Использование технологий «Data Mining» для изучения и предсказания распространения сети магазинов «Wal-Mart»
В статье рассматривается пример использования технологии извлечения знаний из данных «Data Mining». Технология используется для нахождения правил принятия решений по развитию крупной международной сети супермаркетов «Wal-Mart». Эти правила заключаются в оценке вероятности открытия новых торговых точек. Построение оценок вероятности основано на алгоритме «Деревья решений» технологии «Data Mining» . Полученные оценки используются для построения областей достижимости распространения сети магазинов «Wal-Mart».
Работа выполнялась в рамках летней программы молодых учёных 2006 Международного института прикладного и системного анализа (IIASA, Laxenburg, Austria) в рамках совместных исследований программ «Динамические системы» и «Анализ динамики перехода к новым технологиям».
Статья напечатана в журнале Вестник Гуманитарного университета, серия Экономика, №1(7) 2006, стр. 39-70. ISSN 1608-9030.
1. Сведения о сети магазинов «Wal-Mart»
3. Выделение правил модели развития сети из эконометрических данных
3.2. Обзор используемого средства Microsoft SQL Server 2005
3.3. Алгоритмы «Data Mining» реализованные в Microsoft SQL Server 2005:
3.3.2. «Наивный» алгоритм Байеса
3.3.4. Кластеризация последовательности действий
3.4. Методология «CRISP-DM» для процесса «Data Mining»
3.4.1. Фазы процесса «Data Mining» по методологии «CRISP-DM».
3.9. Дерево решений алгоритма «Microsoft Decision Trees»
3.9.1. Алгоритм построения новых ветвей.
3.11. Проверка адекватности модели
3.12. Особенности реализации инфраструктуры моделирования в Microsoft SQL Server 2005.
4. Оценка множества достижимости сети магазинов «Wal-Mart»
Введение
Технология «Data Mining» [5,15,17], предназначенная для извлечения полезной, ранее неизвестной информации из данных наблюдения за системой, является мощной технологией с высоким потенциалом для сосредоточения усилий анализа на наиболее важной информации в хранилищах данных. Средства «Data Mining» описывают тренды и правила поведения, позволяют сделать проактивные решения, основанные на анализе данных. Средства «Data Mining» изучают базы данных на наличие скрытых шаблонов, находя полезную информацию, которую эксперты могут упустить, т.к. это лежит вне их ожиданий.
Сеть «Wal-Mart» является крупнейшей в мире корпорацией в терминах продаж [16,18]. Она упоминается как компания с блестящей логистической системой, оказывающая существенное воздействие на экономику США в целом. В работе изучается развитие сети магазинов «Wal-Mart» во времени и диффузия торговых точек «Wal-Mart», фрагменты которой представлены на рисунках 1,2.
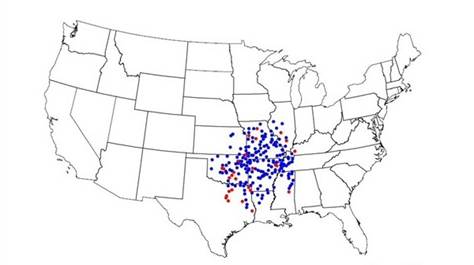
Рис.1. Магазины сети «Wal-Mart» 1978.
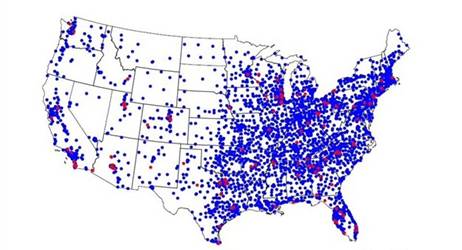
Рис.2. Магазины сети «Wal-Mart» 2004.
Предлагается подход для решения задачи построения комбинаций мест открытия магазинов на уровне округов США (множеств достижимости [2,3,7,10,11,12,13]). Оценивается влияние различных эконометрических [1,4,6,11] параметров округов на частоту открытия в них магазинов сети. Результатом моделирования является система оценок округов, имеющих близкую к нулю вероятность [4] открытия новых магазинов, как показано на рис. 3.
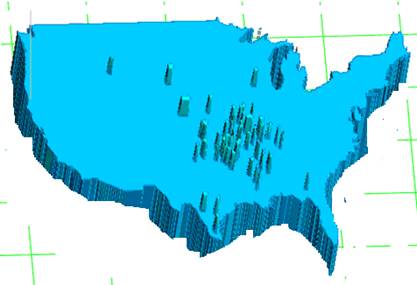
Рис.3. Округа США с низкой вероятностью новых открытий магазинов сети «Wal-Mart» в 2006.
1. Сведения о сети магазинов «Wal-Mart»
Сеть «Wal-Mart» это крупнейшая в мире розничная сеть более чем из 6000 магазинов (в их числе как гипермаркеты, так и универсамы, продающие продовольственные и промышленные товары), расположенных во множестве уголков земли. Основные конкуренты сети «Wal-Mart» на розничном рынке США являются сети Kmart и Target. Стратегия сети «Wal-Mart» включает в себя такие слагаемые как максимальный ассортимент и минимальные, стремящиеся к оптовым, цены.
Сеть «Wal-Mart» является лидером по внедрению технологий, связанных с использованием в торговле RFID-меток. Понятие RFID (Radio Frequency IDentification, радиочастотная идентификация) означает метод удалённого хранения и получения данных посредством передачи радио-сигналов.
По итогам 2004 cеть «Wal-Mart» стала крупнейшей компанией в мире по объёму выручки (в дальнейшем её потеснил ряд нефтяных компаний).
Общая численность персонала компании составила 1,6 млн. человек (2006). Оборот компании в 2005 составил $312,4 млрд., чистая прибыль составила $11,2 млрд.
Представители cети «Wal-Mart» неоднократно подчеркивали важность российского рынка для компании, однако по сей день (июнь 2006) открытие магазинов сети на территории Российской Федерации (РФ) не планируется. Отсутствие интереса у cети «Wal-Mart» к быстрорастущему российскому розничному рынку конечно же выгодно крупным, мелким и средним российским компаниям работающим в этой сфере таким как «Пятёрочка», «Копейка» и прочие. Непосредственную нишу cети «Wal-Mart» в Москве и Московской области заняла французская сеть из 9 гипермаркетов cети «Ашан», которая продолжает увеличивать свой потенциал.

Рис. 4. В овощном отделе гипермаркета сети «Wal-Mart».
Ряд критиков сети утверждает, что сеть «Wal-Mart» способствует вытеснению с рынка мелких торговцев, в том числе маленьких семейных магазинов. Также ряд частных лиц и организаций приводят свидетельства в пользу того, что сеть «Wal-Mart» давит на поставщиков, «выжимая» из них меньшие закупочные цены, магазины сети отрицательно влияют на экологию, а права персонала зачастую нарушаются (см.
2. Структура задачи
Возможно, что в 1972 году решение о выборе места открытия первого магазина и не вызвало сомнений, но в процессе развития сети магазинов вопрос о выборе места для нового супермаркета представляется далеко не тривиальной задачей. Как упоминается в литературе, посвящённой сети «Wal-Mart» [1], компания хранит свои секреты. Поэтому методы принятия решений об открытии магазинов в той или иной точке интересны для изучения.
В целом процесс принятия решения по открытию нового магазина можно представить так, как показано на Рис. 5:
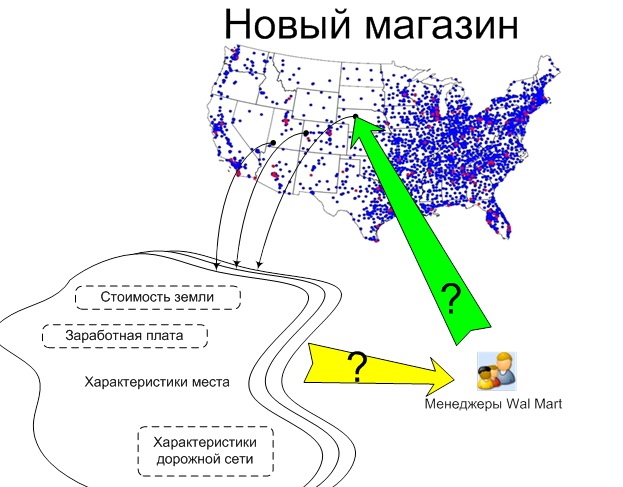
Рис.5. Схема принятия решения по открытию нового магазина сети «Wal-Mart».
Менеджеры рассматривают характеристики различных мест для открытия магазина: доход, который будет приносить магазин; заработную плату; стоимость земли; характеристики дорожной сети; размеры налогов и т.д. После этого принимается решение о постройке нового магазина. Формально этот процесс можно описать как функцию F Wal-Mart, которая по характеристикам места определяет вероятность открытия нового магазина или приоритет открытия магазина в данном месте. Функциональную структуру функции определяют знания и эмпирический опыт менеджеров и экспертов компании. Будем считать, что такая функция существует.
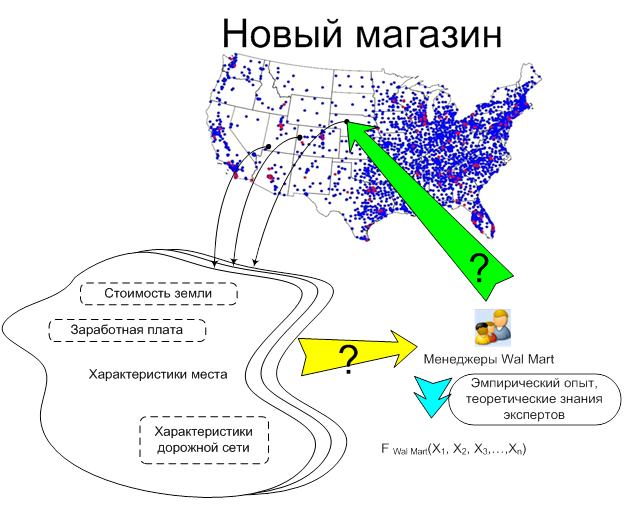
Рис.6. Функция принятия решения по открытию магазина сети.
Основная задача данной работы заключается в построении такой синтетической функции F, которая бы аппроксимировала идеальную функцию FWal-Mart только лишь на основании имеющихся данных по открытию новых магазинов и экономическим параметрам мест открытия.
Отметим, что классические регрессионные методы оценки такие, как метод наименьших квадратов или метод максимального правдоподобия, в случае отсутствия данных по существенным независимым переменным в общем случае дают смещённые оценки параметров и ковариационной матрицы. На практике имеется лишь ограниченный набор данных, и, скорее всего, он отличается от тех данных, которыми располагали менеджеры cети «Wal-Mart», когда принимали решение об открытии нового магазина. Кроме того, данные, которые используются в исследовании, агрегированы до уровня округов США, то есть функция F будет задана на более крупной сетке. В этом случае подходы к моделированию развития сети магазинов такие как, например, модель из [1], применить сложно, т.к. в ней используются данные по стоимости земли, которые задаются на географической сетке с погрешностью в несколько километров. В нашем случае имеются лишь данные о средней стоимости земли в округах площадью до нескольких тысяч квадратных километров. Поэтому в работе предлагается местом открытия магазина считать округ, а не точную географическую координату.
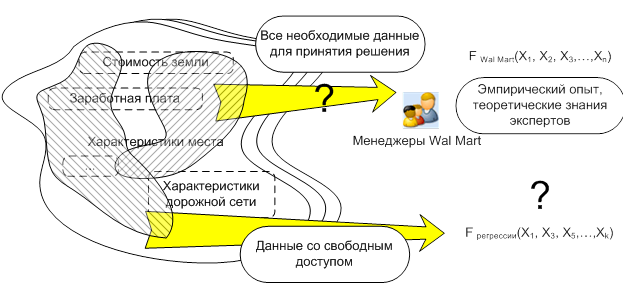
Рис. 7. Ограничения.
Перечисленные ограничения на доступность информации требуют использования других методов, например, методов искусственного интеллекта, для восстановления функции F по имеющимся данным. Использование искусственного интеллекта направлено на выявление новых особенностей поведения объекта в рамках существующей модели или, как в данном случае, на получение начальных сведений для построения модели, когда существующие методы по каким-либо причинам не применимы.
Данное исследование направлено на восстановление функции F Wal-Mart с помощью технологий «Data Mining» . При этом, в некоторых случаях точность функции F, аппроксимирующей функцию F Wal-Mart, может быть невысокой из-за недостатка информации, а в некоторых областях можно с высокой точностью определить взаимосвязь между экономическими параметрами и вероятностью открытия нового магазина в округе. Технологии «Data Mining» позволяет так же описать правила принятия решений по инвестициям в открытие новых магазинов.
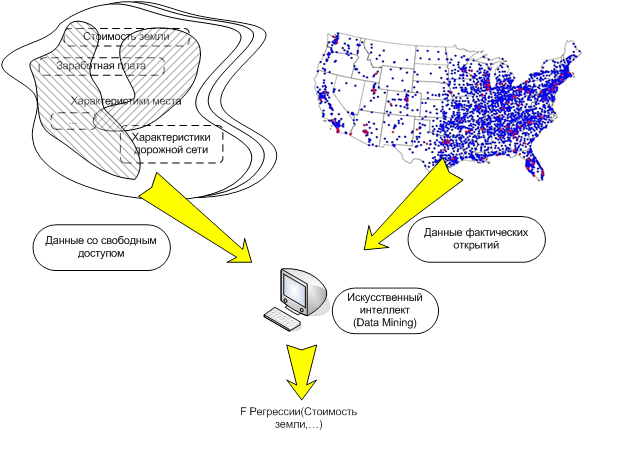
Рис. 8. Структура использования алгоритмов «Data Mining» .
3. Выделение правил модели развития сети из эконометрических данных
В данном разделе рассматриваются этапы процесса «интеллектуальной раскопки данных». Описывается межотраслевой стандарт «Cross Industry Standard Process for Data Mining» (CRISP-DM). Далее обсуждается алгоритм «Microsoft Decision Trees» и указывается его применение к решению задачи описания динамики распространения сети магазинов.
3.1. Технологии «Data Mining»
«Data Mining» является современной технологией анализа информации с целью нахождения в накопленных данных ранее неизвестных, нетривиальных и практически полезных знаний, необходимых для принятия оптимальных решений в различных областях человеческой деятельности.
В процессе «интеллектуальной раскопки данных» анализируется информация с целью автоматического поиска шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналитической обработки данных («OLAP») в «Data Mining» задача по формулировке гипотез и выявлению необычных шаблонов переложена на информационную систему.
В список основных задач, решаемых алгоритмами «Data Mining», входят:
· сегментация (выявление структуры, групп, кластеров);
· поиск ассоциаций (связей между различными характеристиками);
· поиск временных шаблонов;
· регрессия (прогнозирование, классификация, восстановление функциональной зависимости между характеристиками).
Пример объектов исследования «Data Mining».
· Какие товары надо предлагать данному покупателю?
· Какова вероятность того, что данный сектор потенциальных клиентов отреагирует на рекламную кампанию?
· Как оценить риск выдачи кредита данному клиенту банка?
· В чем причины брака в производстве?
3.2. Обзор используемого средства Microsoft SQL Server 2005
Microsoft SQL Server 2005 является комплексным, интегрированным, законченным решением обработки данных, которое включает в себя следующие компоненты:
|
|
Компонент Database Engine (Система управления базами данных) Компонент Database Engine представляет собой основную службу для хранения, обработки и обеспечения безопасности данных. Этот компонент обеспечивает управляемый доступ к ресурсам и быструю обработку транзакций, что соответствует требованиям большинства приложений по обработке данных на предприятии. Кроме того, компонент Database Engine обеспечивает разностороннюю поддержку для поддержания высокого уровня доступности.
|
|
|
Службы Analysis Services(Аналитические службы) Службы Analysis Services предлагают интерактивную аналитическую обработку и интеллектуальный анализ данных для приложений бизнес-аналитики. Analysis Services поддерживают интерактивную аналитическую обработку, позволяя проектировать, создавать и управлять многомерными структурами, содержащими данные, собранные из других источников, таких как реляционные базы данных. Благодаря службам Analysis Services в приложениях интеллектуального анализа данных можно проектировать, создавать и визуализировать модели интеллектуального анализа данных. Разнообразие стандартных алгоритмов интеллектуального анализа данных позволяет создавать такие модели на основе других источников данных.
|
|
|
Службы Integration Services (Службы интеграции) Службы Integration Services — это платформа для создания высокопроизводительных решений по интеграции данных, включая пакеты для хранения данных, обеспечивающие извлечение, преобразование и загрузку данных.
|
|
|
Репликация представляет собой набор технологий, с помощью которых данные или объекты баз данных можно скопировать и перенести из одной базы данных в другую, а затем синхронизировать эти базы данных для обеспечения согласованности. Благодаря репликации данные можно размещать в различных местах, обеспечивая возможность доступа к ним удаленных и мобильных пользователей по локальным или глобальным сетям, посредством коммутируемых и беспроводных соединений и через Интернет.
|
|
|
Службы Reporting Services предлагают предприятиям средства составления отчетов на основе веб-интерфейса, которые позволяют включать в отчеты данные из различных источников, публиковать отчеты в разнообразных форматах, а также централизованно управлять безопасностью и подписками.
|
|
|
Службы Notification Services представляют собой среду разработки и развертывания приложений для создания и отправки уведомления. C помощью этих служб можно создавать и своевременно отправлять индивидуальные сообщения тысячам или миллионам подписчиков, поддерживая доставку на различные устройства.
|
|
|
Компонент Service Broker призван помочь разработчикам в создании безопасных приложений баз данных с возможностью масштабирования. Данная технология использования ядра СУБД предоставляет платформу для обеспечения связи на основе обмена сообщениями, благодаря которой независимые компоненты приложений могут действовать как единое целое. В компонент Service Broker включена инфраструктура асинхронного программирования, которая может использоваться как приложениями в пределах одной базы данных или экземпляра, так и распределенными приложениями.
|
|
|
Функция полнотекстового поиска позволяет выполнять полнотекстовые запросы данных, состоящих из простых символов, в таблицах SQL Server. Полнотекстовые запросы могут включать слова и фразы или несколько форм слов и фраз.
|
Использование компонентов в процессе данного исследования показано на рисунке
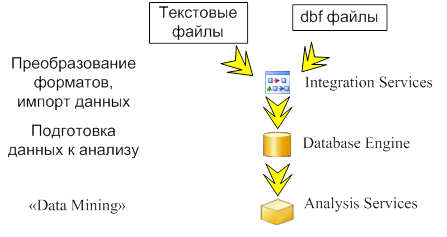
Рис. 9. Использование компонентов Microsoft SQL Server 2005 в процессе исследования.
3.3. Алгоритмы «Data Mining» реализованные в Microsoft SQL Server 2005:
3.3.1. Деревья решений
|
|
Алгоритм предназначен для определения факторов, влияющих в наибольшей степени на определенный атрибут. Предназначен для задач классификации, регрессии, выявления взаимосвязей. Пример: Какие характеристики являются определяющими для лояльного клиента? |
3.3.2. «Наивный» алгоритм Байеса
|
|
Лучше всего предназначен для задач углубленного анализа данных (задачи определения взаимозависимостей атрибутов, классификации, прогноза). Пример: это письмо спам? |
3.3.3. Кластеризация
|
|
Предназначен для сегментации, группировки и классификации данных. Пример: какие группы продаж можно выделить за прошлый год? |
3.3.4. Кластеризация последовательности действий
|
|
Предназначен для выявления групп на основании последовательности действий. Пример: посетителя сайта делятся на группы по типичным «маршрутам» их посещений по категориям. |
3.3.5. Ассоциативные правила
|
|
Предназначен для выявления взаимосвязей между различными характеристиками и их значениями. Пример: Если клиент покупает товар A и B, то с вероятностью 74% он покупает также товар C. |
3.3.6. Нейронные сети
|
|
Предназначен для задач классификации и сегментации. |
3.3.7. Временные ряды
|
|
Предназначен для прогнозирования значений временных последовательностей. Пример: бюджетирование заказов комплектующих на основании прогноза продаж товара. |
3.4. Методология «CRISP-DM» для процесса «Data Mining»
В консорциум, разрабатывающий межотраслевой стандарт CRISP-DM, входит 160 организаций (в том числе
NCR- ведущий поставщик решений в области информационных технологий для банков и мировой лидер в области производства и поставок банкоматов.
SPSS — ведущий поставщик технологий и услуг в области прогностической аналитики
DaimlerChrysler — один из ведущих мировых автопроизводителей, пятый по величине автоконцерн в мире). Методология CRISP-DM разработана именно для процесса «Data Mining» , независимо от области его применения и выбора компьютерной платформы. Эта методология должна помочь компаниям планировать и реализовывать процессы Data Ming на всех уровнях — от постановки проблемы до распространения результатов потребителям. Вместе с тем, методология CRISP-DM сосредотачивается не на технологических аспектах, а на бизнес-методиках проектов «раскопки данных». Сейчас действует версия 1.0 стандарта, готовится версия 2.0 (на момент начала 2007 года).
Согласно предлагаемой методологии, информация, полученная на одном этапе, служит входными данными для следующего этапа. Такой подход позволяет при обнаружении проблем на одной из фаз легко вернуться назад на необходимое число шагов для устранения ошибок или внесения улучшений.
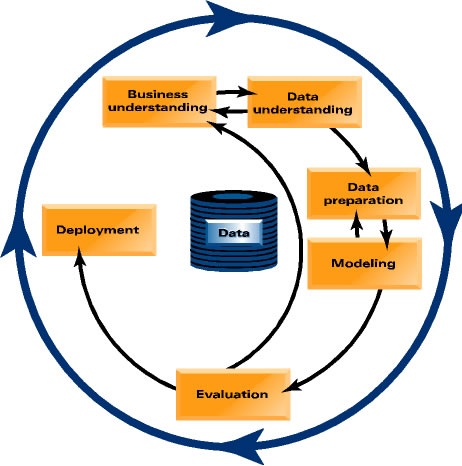
Рис. 9. Жизненный цикл проекта «Data Mining» .
3.4.1. Фазы процесса «Data Mining» по методологии «CRISP-DM».
1. Первый блок включает в себя задачу «понимания бизнеса», которая заключается в формулировке задач и целей проекта, в описании требований бизнеса и преобразовании их в определения на уровне процесса «раскопки данных».
2. Второй блок включает в себя задачу «понимания данных». Эта задача состоит в пробном сборе данных, в понимании структуры информации, в выявлении проблем, связанных с качеством данных, в обнаружении скрытых взаимосвязей.
3. Третий блок связан с «подготовкой данных», которая включает в себя определение задач, ориентированных на формирование конечного набора данных для ввода в программу анализа. Эти задачи могут выполняться многократно, и строгого порядка для них не существует.
4. Четвёртый блок осуществляет «моделирование». Он предполагает отбор наиболее походящих технологий моделирования и тонкую настройку параметров для получения оптимального результата.
5. Пятый блок предназначен для «оценки качества модели». В нём осуществляется построение модели, позволяющей получать приемлемые результаты на основании накопленных данных. Кроме того, производится оценка пригодности модели для задачи принятия бизнес-решений.
6. В шестом блоке обсуждается вопрос возможности «внедрения модели». Проводятся эксперименты по внедрению модели на предприятии для нужд управления бизнесом. Ее результатом могут быть отчеты или комплексные аналитические исследования.
Более подробно о CRISP-DM можно прочитать на странице Cross Industry Standard Process for Data Mining
3.5. Подготовка данных
Подготовка данных является одной из важнейших задач в процессе применения алгоритмов «Data Mining» . На этот этап приходится до 80% времени, затраченного на проект в целом.
Целью данного этапа является преобразование различной информации к виду, доступному для алгоритмов «Data Mining» . Эконометрические данные процесса представляются в самом разнообразном виде — карты, наборы данных, текстовая информация, т. е. в виде информации, доступной и подготовленной, в основном, для человеческого восприятия. Понятным для алгоритмов «Data Mining» видом информации является таблица случаев, в каждой строке которой вписаны аргументы функции и соответствующие значения. На основе таблицы случаев алгоритм делает выводы о влиянии аргументов на значение функции и характере влияния. Проблема заключается в том, что существует бесконечное количество способов представления информации в виде таблицы случаев. Получение аргументов искомой функции и ее значений из эконометрических данных является не тривиальной, в целом, задачей, которая в настоящее время полностью не автоматизирована. В рамках стандартной методологи CRISP-DM выделением параметров, описывающих процесс занимается специалист предметной области.
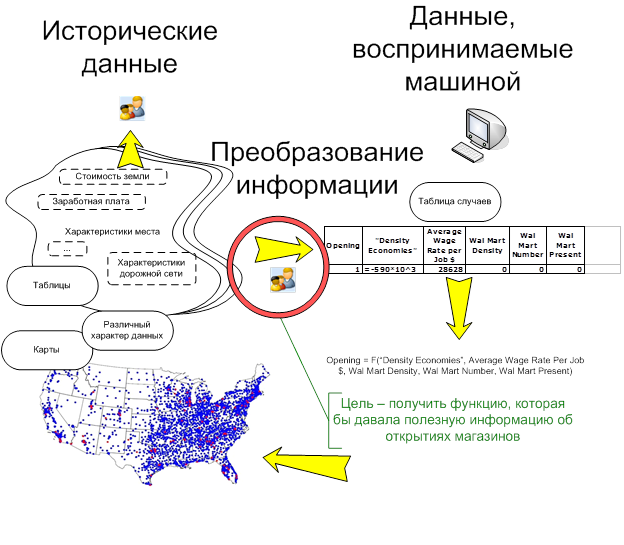
Рис. 10. Задача преобразования информации процесса «Data Mining» .
В рассматриваемом случае имеется карта городов и округов США, информация о местах возникновения сети магазинов «Wal-Mart», экономические параметры округов. В процессе исследования был выбран следующий подход к формированию таблицы случаев.
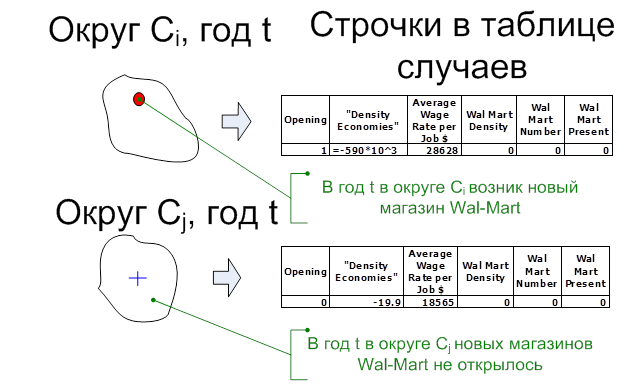
Рис. 11. Построение таблицы случаев для сети магазинов «Wal-Mart».
Распространение сети «Wal-Mart» по округам рассматривается как набор случаев открытия магазина и случаев без открытия магазина в округе. В столбце «Opening» для округа Ci и года t ставится 1, если в округе Ci в течение года t был открыт новый магазин сети «Wal-Mart». Причём, если было открыто два и более магазинов, то для каждого открытия добавляется соответствующая строка в таблицу случаев, т.е. строка повторяется в таблице случаев. Если магазинов открыто не было, то для округа в таблицу случаев заносится строка, в которой значение столбца «Opening» равно 0.
В данном случае вид таблицы случаев выбирается с целью определения влияния параметров «Density Economies» (Экономия за счет плотности), «Average Wage Rate per Job $» (Средняя заработная плата), «Wal Mart Density» (Количесво магазинов сети «Wal-Mart» на душу населения, «Wal Mart Number» (Количесво магазинов сети «Wal-Mart»), «Wal Mart Present» (Присутствие магазина «Wal-Mart») на частоту открытия магазина в произвольно выбранном округе и в произвольно выбранный год. Поэтому эти параметры заносятся в соответствующие строки таблицы случаев. В следующем разделе эти параметры подробно описываются.
Как вариант для формирования таблицы случаев можно также рассматривать поле «Year» (год), которое показывает структуру открытий магазинов в течение года и имеет существенное влияние на частоту открытия магазинов. Однако для поиска общих правил, по которым открывались магазины сети «Wal-Mart» в течение 27 лет, следует исключить поле «Year» из таблицы случаев.
3.6. Описание данных
Процесс распространения сети магазинов «Wal-Mart» в США рассматривается в период с 1973 по 1999 год. Для исследования используются следующие данные:
- данные о городах и их координатах;
- данные о принадлежности города к округу;
- экономические данные округов США за рассматриваемый период;
- данные о присутствии магазина в городе в заданный год.
Для аргументов функции F выбираются следующие параметры округа:
· «Wal-Mart Present» (Присутствие магазина сети «Wal-Mart»)
Этот бинарный параметр описывает присутствие магазина в округе к заданному год t. Значение 0 показывает, что к началу года t в округе не было магазина, а значение 1 соответствует ситуации наличия хотя бы одного магазина в округе к началу года t.
· "Wal-Mart Number«(Количесво магазинов сети «Wal-Mart»)
Этот параметр равен числу магазинов в округе к началу года t.
· "Wal-Mart Density«(Количесво магазинов сети «Wal-Mart» на душу населения)
Этот параметр описывает количество магазинов на душу населения к году t. Он равен отношению количества магазинов в округе к численности населения
![]() Wal-Mart Density =Wal-Mart Number/Население.
Wal-Mart Density =Wal-Mart Number/Население.
· "Average Wage Rate Per Job $"(Средняя заработная плата)
Средняя заработная плата в округе.
· "Density Economies«"(Экономия за счет плотности)
Параметр «Экономия за счет плотности» является важным экономическим параметром и, в частности, в работе [1] исследуется влияние этого параметра на развитие сети магазинов. В данной работе мы используем следующую формулу для вычисления этого параметра:
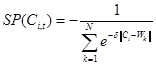
Здесь величина![]() обозначает расстояние между центром выбранного округа
обозначает расстояние между центром выбранного округа ![]() и пятью ближайшими магазинами
и пятью ближайшими магазинами ![]() ,
, ![]() .Параметр
.Параметр ![]() есть параметр угасания эффекта экономии. Значение
есть параметр угасания эффекта экономии. Значение ![]() = 0.2 выбирается согласно аргументам из работы [1]. В работе параметр используется, как безразмерный.
= 0.2 выбирается согласно аргументам из работы [1]. В работе параметр используется, как безразмерный.
Как упоминается в работе [1], компания «Wal-Mart» предпочитает размещать новые магазины в относительной близости к существующей сети. В настоящем исследовании показывается, что параметр «Density Economies» хорошо описывает такое волновое распространение сети также и на уровне округов.
Параметр «Density economies», который описывает близость расположения выбранной точки относительно текущей сети, является значительно более информативным параметром среди других параметров такого же типа. К таким возможным параметрам относятся, например, расстояние от текущей точки до ближайшего магазина, расстояние от текущей точки до географического центра магазинов. Серия компьютерных экспериментов, проведённых для алгоритмов «Data Mining», показывает, что влияние таких параметров расстояния на открытие магазинов является значительно более слабым, чем влияние параметра «Density economies». Результаты этих экспериментов ещё раз подчёркивает важность применения параметров, предложенных в рамках предметной области исследования [1], для описания восстанавливаемой функции.
3.7. Фильтрация данных таблицы случаев. Влияние параметра «Density Economies» на частоту открытия магазинов.
Моделирование показывает, что наибольшее влияние на выбор места для открытия нового магазина имеет параметр «Density Economies». Точка ![]() = - 232725.69 является барьерной точкой параметра по отношению к факту открытия магазинов. В округах со значением «Density Economies», меньшим чем
= - 232725.69 является барьерной точкой параметра по отношению к факту открытия магазинов. В округах со значением «Density Economies», меньшим чем ![]() , не произошло ни одного открытия магазина за рассматриваемый период с 1972 по 1999. Рассматривается таблица случаев с 93399 строками параметров. При этом число строчек со значением параметра «Density Economies», меньшим чем
, не произошло ни одного открытия магазина за рассматриваемый период с 1972 по 1999. Рассматривается таблица случаев с 93399 строками параметров. При этом число строчек со значением параметра «Density Economies», меньшим чем ![]() , составляет величину 39938. Во всех этих случаях не было факта открытия магазина. Число строчек со значением параметра «Density Economies», большим или равным
, составляет величину 39938. Во всех этих случаях не было факта открытия магазина. Число строчек со значением параметра «Density Economies», большим или равным ![]() , составляет величину 53461. Для этих случаев имеются факты открытия магазинов и факты, когда магазины не открывались. Как упоминается в [1] , это обстоятельство указывает на тенденцию открытия нового магазина вблизи к существующей сети. На рис.12 видно, что ограничения на параметр «Density Economies» в 1985 году адекватно описывают места возможных открытий магазинов и являются информативными. Действительно, эти ограничения выделяют часть территории США, в которой открывались магазины.
, составляет величину 53461. Для этих случаев имеются факты открытия магазинов и факты, когда магазины не открывались. Как упоминается в [1] , это обстоятельство указывает на тенденцию открытия нового магазина вблизи к существующей сети. На рис.12 видно, что ограничения на параметр «Density Economies» в 1985 году адекватно описывают места возможных открытий магазинов и являются информативными. Действительно, эти ограничения выделяют часть территории США, в которой открывались магазины.
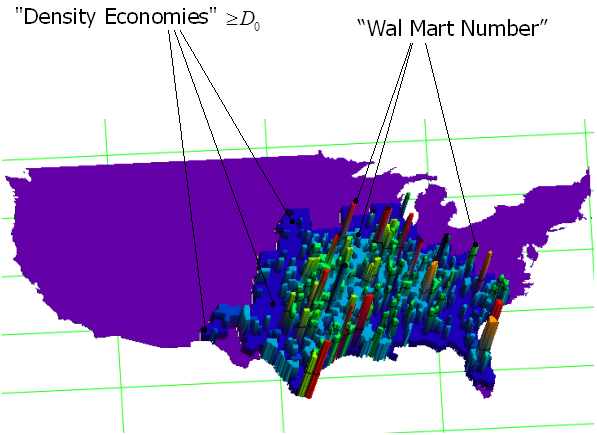
Рис. 12. Зона ограничений параметра «Density Economies» в 1985 году.
Но уже в 1995 разрешенная зона ограничений покрывает большую часть США (см. Рис. 13) и, следовательно, она не является информативной в том смысле, что не локализует места возможных открытий.
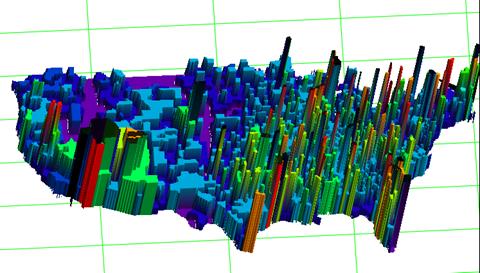
Рис. 13. Зона ограничений параметра «Density Economies» в 1995 году.
Временной тренд наблюдений показывает, что с ростом времени от 1972 года до 1985 года, далее до 1995 года и далее по горизонту прогнозирования, площадь территории, выделяемой ограничениями по параметру «Density Economies», монотонно возрастает и стремится к 100% территории. Таким образом, информативность множества, определяемого барьерным значения ![]() , с ростом времени убывает. В этой динамике возрастает роль остальных модельных параметров «Average Wage Rate per Job $» (Средняя заработная плата), «Wal Mart Density» (количество магазинов сети «Wal-Mart» на душу населения), «Wal Mart Number» (количесвто магазинов сети «Wal-Mart»), «Wal Mart Present» (присутствие магазина «Wal-Mart»). Для построения модели развития уже распространившейся сети необходимо оценить влияние данных параметров на частоту открытия магазинов именно внутри области ограничений параметра «Density Economies».
, с ростом времени убывает. В этой динамике возрастает роль остальных модельных параметров «Average Wage Rate per Job $» (Средняя заработная плата), «Wal Mart Density» (количество магазинов сети «Wal-Mart» на душу населения), «Wal Mart Number» (количесвто магазинов сети «Wal-Mart»), «Wal Mart Present» (присутствие магазина «Wal-Mart»). Для построения модели развития уже распространившейся сети необходимо оценить влияние данных параметров на частоту открытия магазинов именно внутри области ограничений параметра «Density Economies».
Решение задачи фильтрации данных по параметру «Density Economies» заключается в том, что из дальнейшего анализа исключатся строчки таблицы случаев, для которых значение параметра «Density Economies» строго меньше чем ![]() . Для таких строк параметр «Density Economies» довольно точно локализует места открытия магазинов. Для случаев, в которых параметр «Density Economies»
. Для таких строк параметр «Density Economies» довольно точно локализует места открытия магазинов. Для случаев, в которых параметр «Density Economies» ![]() , влияние значения этого параметра мало и предлагаемый алгоритм выявляет правила открытия магазинов в зависимости от значений остальных модельных параметров.
, влияние значения этого параметра мало и предлагаемый алгоритм выявляет правила открытия магазинов в зависимости от значений остальных модельных параметров.
3.8. Выбор алгоритма
Существуют различные алгоритмы «Data Mining» для работы с дискретной и непрерывной предсказываемой (эндогенной) переменной. Предсказываемая переменная «Opening» является бинарной и принимает значения 0 и 1. В работе используется наиболее популярный алгоритм для прогнозирования значений дискретной предсказываемой переменной, который называется алгоритмом деревьев принятия решений. («Microsoft Decision Trees»). Алгоритм «Microsoft Decision Trees» часто выступает в качестве начальной точки исследования данных. В своей основе алгоритм «Microsoft Decision Trees» является алгоритмом классификации. Этот алгоритм хорошо работает для прогнозирования как дискретных, так и непрерывных предсказываемых переменных. При построении модели алгоритм анализирует влияние каждой предсказывающей (экзогенной) переменной в наборе данных на прогнозируемую переменную.
3.9. Дерево решений алгоритма «Microsoft Decision Trees»
Целью алгоритма является разбиение таблицы случаев на наборы строчек, в каждом из которых присутствуют только строчки с открытиями ("Opening"=1) или строчки без открытия ("Opening«=0). Дерево решений рекурсивно разделяет области пространства предсказывающих переменных на подобласти таким образом, что каждая вершина дерева соответствует при этом подобласти пространства предсказывающих переменных. Корень дерева соответствует всему пространству предсказывающих переменных.
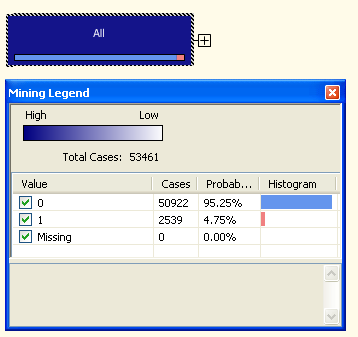
Рис. 14. Распределение случаев в корневом узле дерева решений.
Потомки корня дерева делят пространство предсказывающих переменных на непересекающиеся области. Далее этот процесс деления итеративно применяется к каждому потомку.
Пусть ![]() есть множество всех случаев. Дадим общее описание алгоритма построения новых ветвей в этом множестве
есть множество всех случаев. Дадим общее описание алгоритма построения новых ветвей в этом множестве ![]() .
.
3.9.1. Алгоритм построения новых ветвей
1. Ищется наиболее информативная предсказывающая переменная ![]() .
.
2. Множество значений предсказывающей переменной ![]() делится на непересекающиеся интервалы
делится на непересекающиеся интервалы ![]() .
.
3. Множество ![]() расщепляется на подмножества
расщепляется на подмножества ![]() ,
,![]() ,...,
,..., ![]() , так, чтобы во всех случаях из подмножества
, так, чтобы во всех случаях из подмножества ![]()
![]() предсказывающая переменная
предсказывающая переменная ![]() входила одинаковые интервалы значений
входила одинаковые интервалы значений ![]() .
.
4. Для каждого множества ![]() определяется количественное преобладание случаев с «Opening =1» или «Opening =0». Далее создается лист дерева решений, при этом, лист помечается меткой «Opening =1», если преобладают случаи с «Opening =1», и — меткой «Opening =0» в противном случае. Если преобладания не выявлено, то алгоритм рекурсивно переходит к шагу 1, положив
определяется количественное преобладание случаев с «Opening =1» или «Opening =0». Далее создается лист дерева решений, при этом, лист помечается меткой «Opening =1», если преобладают случаи с «Opening =1», и — меткой «Opening =0» в противном случае. Если преобладания не выявлено, то алгоритм рекурсивно переходит к шагу 1, положив ![]() =
= ![]() .
.
Алгоритм заканчивает работу, когда все подмножества помечены, либо отсутствуют предсказывающие переменные, удовлетворительно разделяющие непомеченные множества.
Функция, используемая для выбора каждого очередного атрибута — кандидата ![]() , должна увеличивать (по сравнению с исходной ситуацией) информацию о зависимости предсказываемой переменной от предсказывающих переменных. Для оценки информативности предсказывающей переменной используется информационная функция полезности.
, должна увеличивать (по сравнению с исходной ситуацией) информацию о зависимости предсказываемой переменной от предсказывающих переменных. Для оценки информативности предсказывающей переменной используется информационная функция полезности.
Пусть ![]() есть вероятность того, в случайно взятом из
есть вероятность того, в случайно взятом из ![]() случае «Opening =1», а
случае «Opening =1», а ![]() - «Opening =1». Она может быть оценена относительной частотой
- «Opening =1». Она может быть оценена относительной частотой
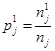 ,
,
где ![]() есть число примеров с «Opening =1» в Sj и nj есть число случаев в Sj.
есть число примеров с «Opening =1» в Sj и nj есть число случаев в Sj.
Энтропия (по Шеннону) подмножества Sj вычисляется по следующей формуле:
![]() .
.
Пусть значения атрибута Ai расщепляют множество S примеров на подмножества Sj. Тогда энтропия семейства подмножеств Sj порожденных значениями Ai есть:
![]()
где ![]() оценивается отношением мощностей подмножеств Sj к мощности S:
оценивается отношением мощностей подмножеств Sj к мощности S:
![]()
Увеличение информации при таком расщеплении происходит благодаря уменьшению энтропии:
![]()
где ![]() есть априорная (до расщепления) энтропия S.
есть априорная (до расщепления) энтропия S.
Величина энтропии в алгоритме используется для поиска оптимальной предсказывающей переменной в смысле разделения множества ![]() . Определяется такая предсказывающая переменная, расщепление посредством которой максимизирует энтропию при делении множества примеров на подмножества.
. Определяется такая предсказывающая переменная, расщепление посредством которой максимизирует энтропию при делении множества примеров на подмножества.
Наиболее информативной предсказывающей переменной оказывается параметр средней заработной платы «Average Rate Per Job». Алгоритм выделяет 4 набора случаев и соответствующих новых узлов дерева по этому параметру, как показано на Рис. 15. Для каждого нового узла имеется правило отнесения случая к этому узлу. Для верхнего и нижнего узла алгоритм не может выделить параметр для разделения, при котором «чистота» узлов увеличилась бы, и оставляет эти узлы листьями дерева.
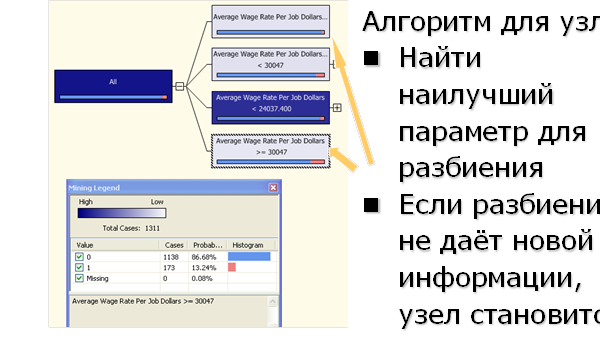
Рис. 15. Построение дерева решений.
Таким образом разбиения продолжаются, пока есть неразбитые узлы, не являющиеся листьями. На рисунках 15, 16, 17 можно увидеть результаты работы алгоритма «Microsoft Decision Trees».
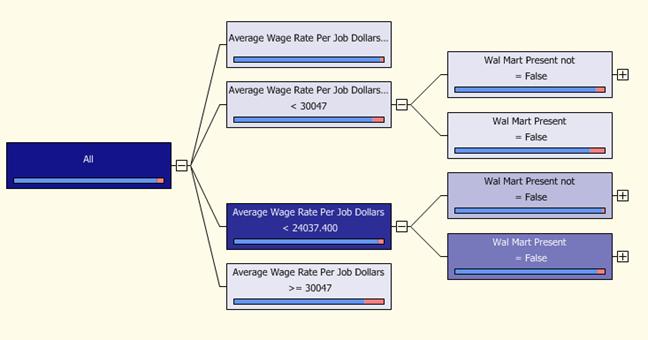
Рис. 16. Рост дерева решений сети магазинов «Wal-Mart».
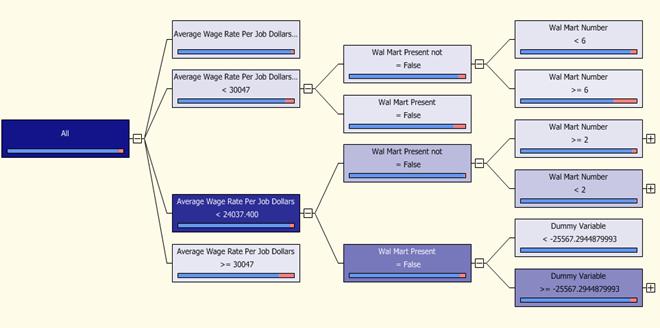
Рис. 17. Рост дерева решений сети магазинов «Wal-Mart».
3.10. Модель развития сети
В модели развития сети используются наиболее чистые узлы дерева и, как оказывается, с данными параметрами хорошо определяются области, в которых частота открытия магазинов является минимальной. Такие чистые узлы приведены в таблице 1.
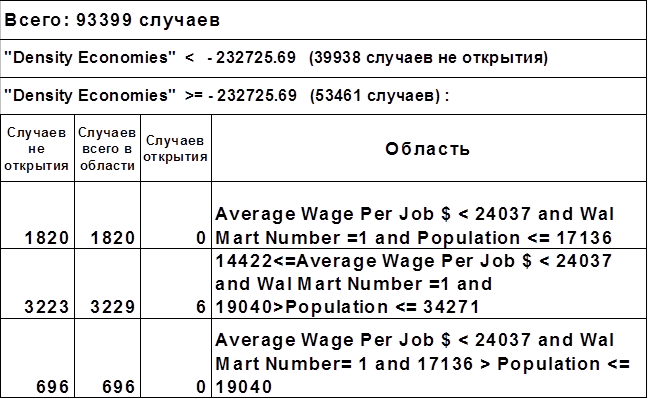
Таблица 1. Параметры наиболее «чистых» узлов дерева. Средняя заработная плата
«Average Wage Per Job» измеряется в долларах, население «Population» измеряется в количестве человек.
Рассмотрим пространство ![]() , одна координата в котором является численностью населения, вторая — средним уровнем заработной платы. Символом
, одна координата в котором является численностью населения, вторая — средним уровнем заработной платы. Символом ![]() обозначим область в этом пространстве
обозначим область в этом пространстве ![]() , которая задается ограничениями правого столбца таблицы 1. Область
, которая задается ограничениями правого столбца таблицы 1. Область ![]() приведена на рисунке 18.
приведена на рисунке 18.
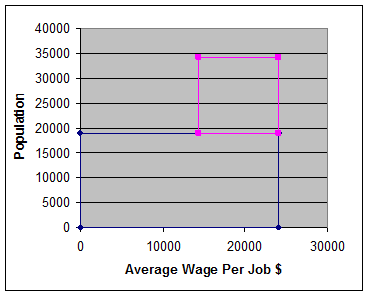
Рис. 18. Область пространства предсказываемых переменных с низкой частотой открытия магазинов.
Дальнейшие рассуждения проводятся в предположении о том, что открытия магазинов в области ![]() являются случайными независимыми событиями. Рассчитаем при этом предположении интервальную оценку вероятности открытия магазинов в округах с количеством магазинов сети «Wal-Mart» равным 1 и экономически находящимися в области
являются случайными независимыми событиями. Рассчитаем при этом предположении интервальную оценку вероятности открытия магазинов в округах с количеством магазинов сети «Wal-Mart» равным 1 и экономически находящимися в области ![]() .
.
Частота открытия магазинов в области ![]() равна отношению количества открытий в области
равна отношению количества открытий в области ![]() к общему числу случаев (см. таблицу 1)
к общему числу случаев (см. таблицу 1)
![]()
Границы интервала, в котором заключено истинное значение вероятности открытия, определяются следующим образом:
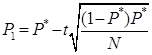 ,
, 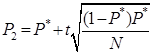 .
.
Здесь квантиль ![]() находится, исходя из заданной доверительной вероятности
находится, исходя из заданной доверительной вероятности ![]() :
:
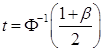
Функция ![]() — функция Лапласа
— функция Лапласа
При вероятности ![]() находим квантиль
находим квантиль ![]()
Умножая это значение на величину
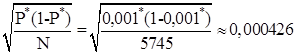
получаем радиус доверительного интервала 0.0006.
Таким образом, вероятность открытия магазина в округе с одним существующим магазином и экономически располагающегося в области R содержится в доверительном интервале (0.0004,0.0017).
3.11. Проверка адекватности модели
Для проверки адекватности метода был проведен следующий эксперимент. Были взяты данные по открытиям магазинов за
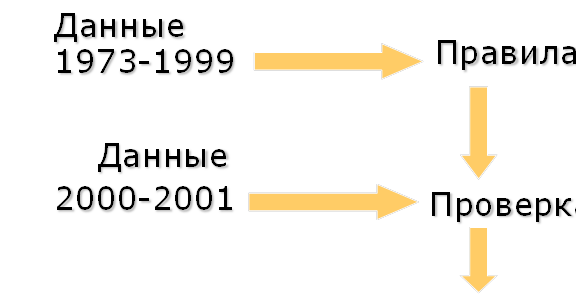
Рис.18. Методика проверки модели на данных, не входящих в обучающий период.
Эксперимент показывает, что те округа, в которых отсутствует открытие магазинов Wal-Mart в
3.12. Особенности реализации инфраструктуры моделирования в Microsoft SQL Server 2005
В соответствии с методологией процесса «CRISP-DM», процесс проекта «Data Mining» является циклическим, в котором процедура добавления новых данных к исследованию может повторяться много раз, после обозрения полученных результатов моделирования.
После обзора результатов моделирования возникает либо необходимость добавления новых данных к таблице случаев, либо настройка параметров используемого алгоритма, таких как, например, минимальное количество строчек, относящееся к узлу дерева решений.
В обоих случаях возникает необходимость оптимизации времени, затраченного компьютером, для подготовки таблицы случаев. Самым медленным вариантом здесь является прямое изъятие данных из исходных источников и расчёт значений предсказываемых переменных в процессе обращения к таблице случаев. При таком подходе таблица случаев на уровне базы данных представляет собой представление (view) в котором посредством обращения к таким же динамическим объектам базы данных как, например функциям, связываются различные исходные данные. Это же вариант является самым гибким и требующим меньшего контроля со стороны исследователя: при изменении исходных данных можно непосредственно обращаться к таблице случаев и получать конечные значения предсказывающих переменных.
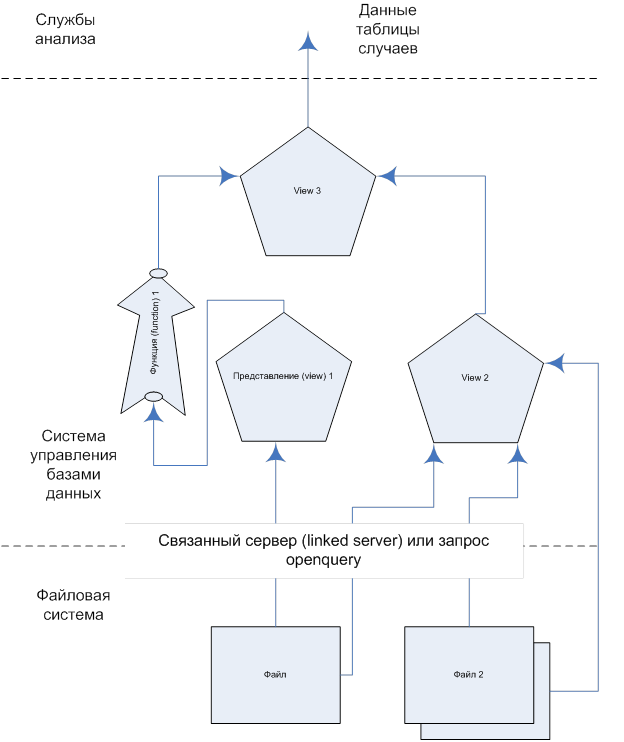
Рис. 19. Динамическое создание таблицы случаев. Возможность обращения к таблице случаев сразу после изменения данных/элементов преобразования. Происходит полный расчёт при каждом обращении к таблице случаев. Использование представлений, функций и связанных серверов.
Другой крайний вариант построения инфраструктуры моделирования предполагает использование хранимых процедур (stored procedures) и пакетов служб интеграции (SQL Server Integration Service Package) на каждом этапе преобразования исходных данных к интерфейсу таблицы случаев. В этом случае данные после каждого этапа трансформации сохраняются в таблицу. В таблице так же создаются индексы, что обеспечивает быстрый поиск данных по условию и отсутствие необходимости выполнять вычисления предыдущих уровней. С другой стороны, при изменении структуры данных/добавлении возникает необходимость запуск вручную цепочки процедур обеспечивающей внесение изменения в конечную таблицу случаев. Кроме того при таком подходе суммарное время, затрачиваемое на первоначальный запуск системы уменьшается за счёт возможности ручных внесений изменений в промежуточные таблицы, когда изменения затрагивают данные, которые же есть. В отличие от динамической конфигурации, когда необходимо писать общий алгоритм обработки данный, учитывая, что могут добавиться новые данные или измениться старые.
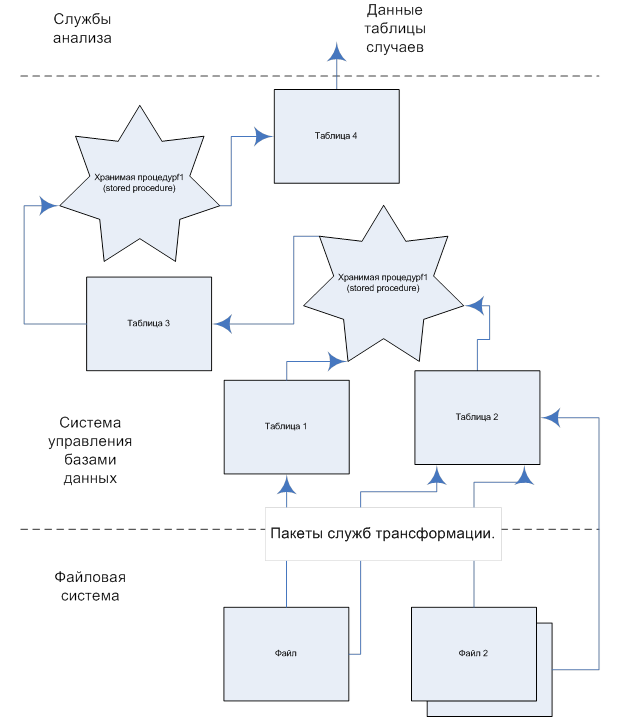
Рис. 20. Создание таблицы случаев путём последовательного перенесения данных через промежуточные таблицы. Высокая скорость каждого этапа. Необходимость ручного запуска цепочки трансформации от места изменения данных. Отсутствие пересчёта данных на нижележащих уровнях.
Такую конфигурацию можно так же назвать статической за счёт сильного использования статических объектов базы данных — таблиц.
Таким образом, задача разработчика системы — уменьшить суммарное время, затрачиваемое в ходе создания и эксплуатации системы. Пусть динамичность использованной структуры оценивается от 1 до 10, где 10 обозначает динамическую структуру, в которой не используется таблиц вообще, а 10 соответствует структуре, в которой каждая композиция функций при переносе данных от файлового источника до интерфейса таблицы случаев, использует таблицы для хранения результатов промежуточных вычислений. Процесс принятия решения по выбору тех или иных методов проектирования поясняется рисунком 21.
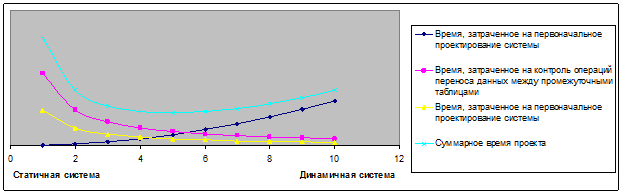
Рис. 21. Затраты времени в проекте «Data Mining», в зависимости от использованной структуры механизмов преобразования данных
На рисунке 22 представлена схема преобразования данных, реализованная в проекте.
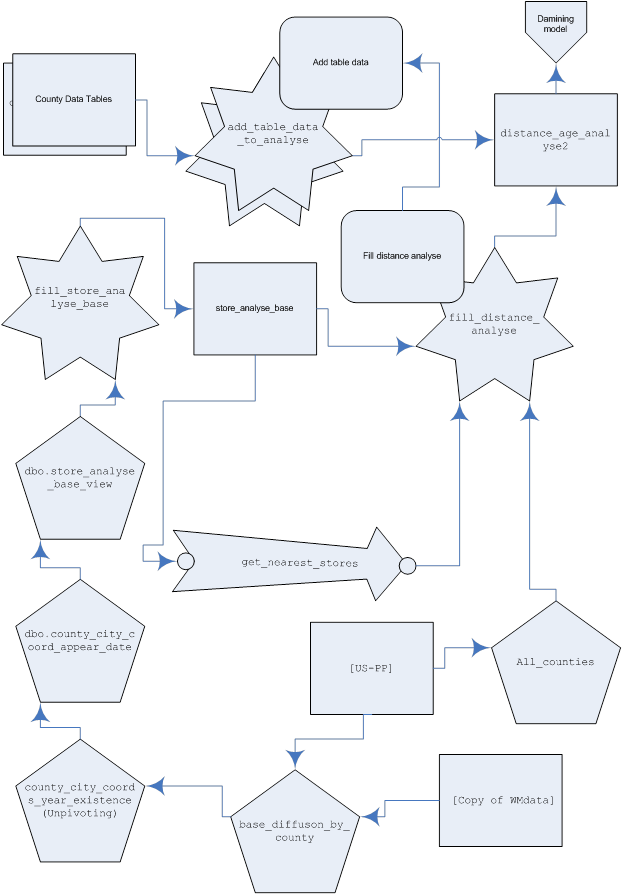
Рис. 22. Схема использования объектов базы данных проекта «Data Mining».
4. Оценка множества достижимости сети магазинов «Wal-Mart»
Как результат анализа процесса «Data Mining» получается модель распространения сети, которая определяет округа США, в которых вероятность открытия нового магазина содержится в доверительном интервале (0.0006,0.0014). В данном разделе будет введено понятие множества достижимости сети магазинов «Wal-Mart» и дана его оценка на ближайшие периоды с использованием полученной модели.
Множество достижимости ![]() в момент времени
в момент времени ![]() состоит из пар (номер округа, количество магазинов в округе на момент времени
состоит из пар (номер округа, количество магазинов в округе на момент времени ![]() ), в которых количество магазинов больше нуля. А именно, множество достижимости
), в которых количество магазинов больше нуля. А именно, множество достижимости ![]() определяется формулой
определяется формулой
![]()
Здесь
![]() -год,
-год,
![]() -номер округа,
-номер округа,
![]() — количество округов,
— количество округов,
![]() — количество магазинов сети «Wal-Mart» в округе
— количество магазинов сети «Wal-Mart» в округе ![]() в год
в год ![]()
Задачей данного раздела является оценка множества достижимости на периоды, не входящие по времени в имеющиеся исторические данные, с использованием оценок численности населения и среднего уровня заработной паты.
Пусть ![]() — последний год, на который известна информация по расположению магазинов по округам. Далее строятся оценки для множества достижимости сети на год
— последний год, на который известна информация по расположению магазинов по округам. Далее строятся оценки для множества достижимости сети на год ![]() .
.
Обозначим символом ![]() средний уровень заработной платы округа
средний уровень заработной платы округа ![]() в год
в год ![]() , а символом
, а символом ![]() численность населения округа
численность населения округа ![]() в год
в год ![]() .
.
Пусть количество магазинов в округе ![]() в год
в год ![]() равно 1,
равно 1, ![]() =1. Для использования модели для года
=1. Для использования модели для года ![]() необходимо, чтобы в округе
необходимо, чтобы в округе ![]() не открывалось новых магазинов и пара, состоящая из заработной платы и численности населения, лежала в области
не открывалось новых магазинов и пара, состоящая из заработной платы и численности населения, лежала в области ![]() , задаваемой таблицей 1,
, задаваемой таблицей 1, ![]() ,
,![]() .
.
Тогда вероятность ![]() открытия нового магазина в округе
открытия нового магазина в округе ![]() за период
за период ![]() определяется формулой
определяется формулой
![]() =
= ![]()
На рис. 19 и изображены округа, в которых модель предсказывает самую низкую вероятность открытия в 2006 году. Перечень этих округов приведён в таблице 2.
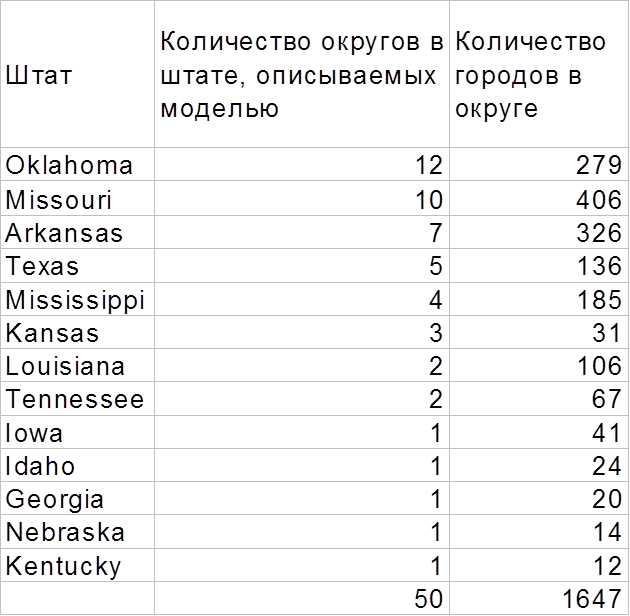
Таблица 2. Названия штатов и количество городов в штатах, в которых в 2006 году предполагается наиболее низкая вероятность открытия нового магазина.
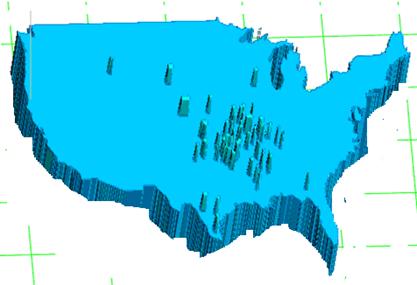
Рис.19. округа США c низкой вероятностью открытия магазинов сети «Wal-Mart» в 2006.
Следует заметить, что с течением времени средняя заработная плата и численность населения в большинстве округов увеличиваются и, соответственно, выходят из зоны ![]() . На рисунке 20 красными линиями показаны эконометрические траектории округов которые не описываются данной моделью. Зелёными показаны эконометрические траектории округов, для которых выполняется условие
. На рисунке 20 красными линиями показаны эконометрические траектории округов которые не описываются данной моделью. Зелёными показаны эконометрические траектории округов, для которых выполняется условие ![]() ,
,![]() и модель прогнозирует наименьшую вероятность отекрытия магазинов.
и модель прогнозирует наименьшую вероятность отекрытия магазинов.
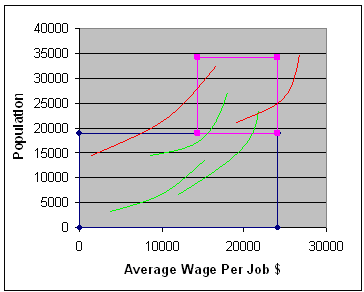
Рис. 20. Изменения
Таким образом, с течением времени вероятность открытия нового магазина в попадающих под ограничение округах, увеличивается.
5. Заключение
Задачей настоящей статьи является исследование правил принятия решений распространения крупной международной сети супермаркетов «Wal-Mart». Полученные правила используются для оценки множества достижимости сети магазинов на будущие периоды. В качестве инструмента анализа используется алгоритм построения дерева решений «Microsoft Decision Trees». Рассматривается методология межотраслевого стандарта «Cross Industry Standard Process for Data Mining» (CRISP-DM) для организации процесса «интеллектуальной раскопки данных Data Mining» и особенности процесса применительно к исследованию развития сети магазинов «Wal-Mart». Вводится понятие множества достижимости сети магазинов и даётся его вероятностная оценка на будущие периоды, основанная на оценках численности населения и среднего уровня заработной платы.
Список литературы
1. Айвазян С.А., Мхитарян В.С. Прикладная статистка и основы эконометрики. М.: ЮНИТИ, 1998.
2. Благодатских В.И. Введение в оптимальное управление. М.: Высшая школа, 2001.
3. Вдовин С.А., Тарасьев А.М., Ушаков В.Н. Построение множества
достижимости интегратора Брокетта. Прикладная математика и механика. Том 68. Вып. 5 2004.
4. Венцель Е.С. Теория вероятностей. М.: Высшая школа, 1999.
5. Дюк В., Самойленко А. Data Mining: учебный курс. С.-П.: ПИТЕР, 2001.
6. Интрилигатор М. Математические методы оптимизации и экономическая теория. М.: АЙРИС ПРЕСС, 2002.
7. Красовский Н.Н., Субботин А.И. Позиционные дифференциальные игры. М.: Наука, 1974.
8. Крушвиц Л. Финансирование и инвестиции. С.-П. : ПИТЕР, 2000.
9. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. М.: Дело, 2000.
10. Понтрягин. Л.С., Болтянский В.Г., Гамкрелидзе Р.В., Мищенко Е.Ф. Математическая теория оптимальных процессов. М.: Наука, 1976.
11. Тарасьев А.М., Ушаков В.Н., Вдовин С.А. Сопряжённые производные минимаксных решений уравнений Гамильтона-Якоби в задаче интегратора Брокетта. Вестник УГТУ-УПИ«, № 6(77).
12. Тарасьев А.М., Успенский А.А., Ушаков В.Н. Аппроксимационные схемы и конечно-разностные операторы для построения обобщенных решений уравнений Гамильтона — Якоби // Изв. РАН. Техн. кибернетика, 1994. N 3. С.
13. Субботин А.И., Тарасьев A.M., Ушаков В.Н. Обобщенные характеристики уравнений Гамильтона-Якоби. // Изв. АН. Техн.кибернетика. 1993. No. 1. С.
14. Шарп У.Ф., Александер Г.Дж., Бэйли Д.В. Инвестиции. М.: ИНФРА-М, 1999.
15. Han, J., Kamber, M., Data Mining: Concepts and Techniques, 2nd edition. Morgan Kaufmann Publishers, 2006.
16. Thomas, J. The Diffusion of «Wal-Mart» and Economies of Density. Society for Economic Dynamics, Series of 2006 Meeting Papers, No. 15. http://walmartwatch.com/blog/archives/wal_mart_growth
17. Tang, Z., MacLennan J., Data Mining with SQL Server 2005. Wiley, 2005.
18. Wikipedia (свободная энциклопедия). Статья «Wal-Mart». http://en.wikipedia.org/wiki/Wal-Mart